Query and ORM operations¶
UtilMeta implements a unique and efficient declarative Schema query mechanism to quickly develop CRUD RESTful APIs. We can see the concise case code of declarative ORM and API in UtilMeta Framework Homepage
In this document, we will explain the corresponding usage in detail.
Overview of ORM¶
One of the most common requirements in backend development is to provide RESTful APIs to create, delete, update and retrieve data, and ORM (Object Relational Mapping, object-relational mapping) is a common way to map tables in relational databases to object-oriented programming (such as classes in Python). It is convenient for us to develop the CRUD API, and also eliminates the problems of SQL injection compared with SQL splicing.
We use Django ORM (which is common in Python Web) as an example of how to define a user model and a article model in a simple blog application.
from django.db import models
class User(models.Model):
username = models.CharField(max_length=20, unique=True)
class Article(models.Model):
author = models.ForeignKey(
User, related_name="articles",
on_delete=models.CASCADE
)
content = models.TextField()
- A field
usernameof typeVARCHAR(20)is declared in the User model, and the value of the field is unique (unique=True) - A foreign key named
authorpointing to the User model is declared in the Article model to represent the author of the article. Its reverse relationship is"articles", which represents "all articles" of a user. When the corresponding author user is deleted, the article will be deleted cascadely (CASCADE).
Tip
Detailed usage of Django ORM can refer to Django Queries, but even if you are not familiar with that, you can still continue to learn UtilMeta's declarative ORM
this document will basically revolve around the Django model in The Realworld Blog Project , such as users, articles, comments, follows, etc.
UtilMeta Declarative ORM¶
UtilMeta’s declarative ORM allows you to use the Schema class to declare the data structure of the expected query result in advance, and then you can directly call the method of the Schema class to query the data you need. Let’s still use the model example declared above for simple declarative ORM usage.
from utilmeta.core import api, orm
from .models import User, Article
from django.db import models
class UserSchema(orm.Schema[User]):
username: str
articles_num: int = models.Count('articles')
class ArticleSchema(orm.Schema[Article]):
id: int
author: UserSchema
content: str
We use orm.Schema[<model_class>] to inject the model into the ORM Schema, which are
UserSchema: injected User model with fields
username: corresponds to the same-name field of the user model and serializes it to thestrtypearticles_num: An expression field that queries the number of articles for a user, usingCountto query the reverse relationship ("articles") of the author field.
ArticleSchema: injected Article model with fields
id: instance's primary key, whether defined in the model or not, the default name of the primary key field isidauthor: the author field, which useUserSchemaas the type annotation, to serialize the corresponding author of the article using UserSchema.content: the content field
If you declare an attribute with the same name as a model field in the Schema class, the corresponding field will be serialized to the declared type. For a relationship field such as a foreign key, you can choose to serialize only the foreign key value, or specify a Schema class to serialize the entire relationship object. There are other field usages that we’ll look at below.
Tip
When writing the ORM schema for the model, we actually think about what kind of data structure the client needs. For example, for UGC content like articles, we often need to sequence the authors together and return them, so that the client can directly display them (instead of using ID to query the user API once), So the author field in the example returns the entire user object
orm.Schema methods¶
Now that we know the basic declaration methods of orm.Schema, let’s introduce the important methods of classes or instances. By calling these methods, you can query, create, update, and save data in batches.
init - Single object¶
The Schema.init(obj) method will serializes the passed object parameters to A single Schema instance, where the object parameters can be passed in as
- The ID value, for example
ArticleSchema.init(1)will serializes the article object with ID 1 into anArticleSchemainstance - A Model instance
- A QuerySet, which will serializes the first object of the QuerySet into a Schema instance
The first snippet of UtilMeta Framework Homepage contains a call to init a method or its asynchronous variant ainit.
class ArticleAPI(api.API):
async def get(self, id: int) -> ArticleSchema:
return await ArticleSchema.ainit(id)
class ArticleAPI(api.API):
def get(self, id: int) -> ArticleSchema:
return ArticleSchema.init(id)
The method get in the example directly passes the ID parameter of the request to the ainit method of ArticleSchema, which can directly serialize the article instance with ID 1.
!!! tip “Asynchronous query method”
Every query methods in orm.Schema has its async variant, only need to prepend an a to the method name, such as ainit, aserialize, asave, async methods can only be called in the async def functions, and need to use await for the result
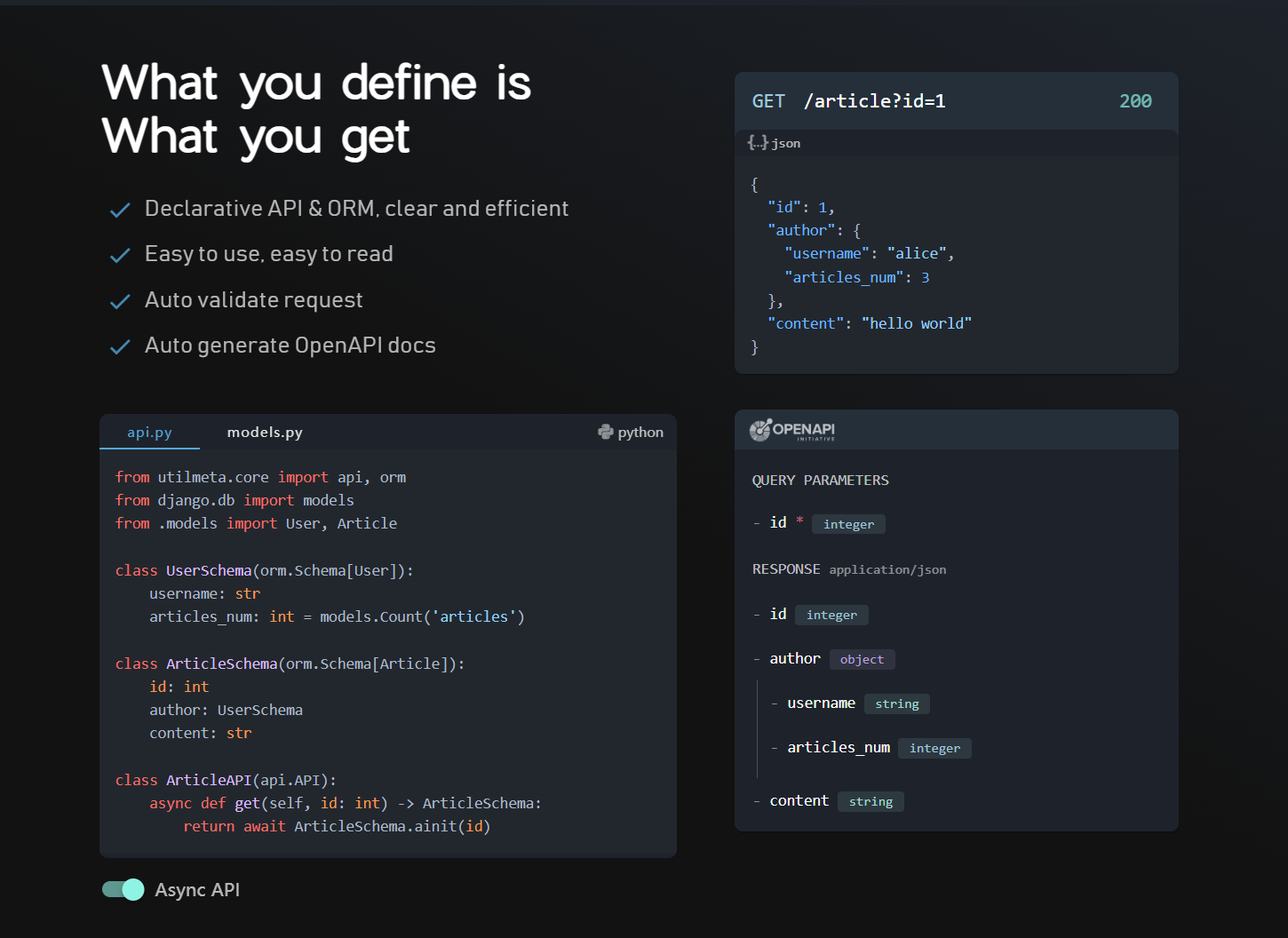
So if the path to the ArticleAPI is /article, when we request GET /article?id=1, we'll get something like the following JSON data result
{
"id": 1,
"author": {
"username": "alice",
"articles_num": 3
},
"content": "hello world"
}
This result is completely consistent with the declaration of ArticleSchema, which shows the core idea of declarative ORM: What you define is what you get
serialize - List of objects¶
Schema.serialize(queryset) serializes a QuerySet into a list of Schema instances, which is a very common method that used when the API needs to return list data
When you use Django ORM, serialize accept a Django QuerySet (of the consistent ORM model). For example, for ArticleSchema, the accepted parameter should be a Article QuerySet. Here is an example.
class ArticleAPI(API):
@api.get
async def feed(self, user: User = API.user_config,
limit: int = utype.Param(10, ge=0, le=50)) -> List[ArticleSchema]:
return await ArticleSchema.aserialize(
Article.objects.filter(author__followers=user)[:limit]
)
class ArticleAPI(API):
@api.get
def feed(self, user: User = API.user_config,
limit: int = utype.Param(10, ge=0, le=50)) -> List[ArticleSchema]:
return ArticleSchema.serialize(
Article.objects.filter(author__followers=user)[:limit]
)
The feed endpoint in example will return the articles published by the author that the current user follows. We just need to pass the constructed QuerySet to the ArticleSchema.serialize method, and we will get a list of ArticleSchema instances. which will be processed as a JSON response to the client.
Tip
It is not this document's focus on how to get the user of current request, you can find detailed usage in Request Authentication
save - Save to database¶
orm.Schema instance can call save() to save the contained data to the corresponding table. If the Schema instance contains a primary key in the data table, the corresponding table record will be updated. Otherwise, a new table record will be created.
In addition to the default behavior based on the primary key, you can adjust the behavior of save through two parameters
must_create: If set to True, the method is forced to be processed as a creation method, although an error is thrown if the data contains a primary key that has already been created.must_update: If set to True, the method is forced to be processed as an update method, and an error is thrown when the update cannot be completed, such as when the primary key is missing or does not exist.transaction: you can set to True or a database connection name to enable the transaction for that database, default is False, set to True will enable transaction for the default database of the corresponding modelusing: Set a database connection name to specify the database to save, by default will be the default database of the corresponding model (defaultin Django ORM)
Tip
The name of a database connection is the dict key defined in the DatabaseConnections configuration, like 'default'
The following example shows save the use of the method in the interface by writing and creating the article API.
from utilmeta.core import orm
from .models import Article
class ArticleCreation(orm.Schema[Article]):
content: str
author_id: int = orm.Field(no_input=True)
class ArticleAPI(API):
async def post(self, article: ArticleCreation = request.Body,
user: User = API.user_config):
article.author_id = user.pk
await article.asave()
return article.pk
from utilmeta.core import orm
from .models import Article
class ArticleCreation(orm.Schema[Article]):
content: str
author_id: int = orm.Field(no_input=True)
class ArticleAPI(API):
def post(self, article: ArticleCreation = request.Body,
user: User = API.user_config):
article.author_id = user.pk
article.save()
return article.pk
In this example, we defined the ArticleCreation class first, which includes a content field and an author field author_id, where the author field has no_input=True configured to ignores input from the client, because typically for this content creation API, The current requesting user is directly used as the author field of the new content, so there is no need for the client to provide
In the post method, we also assign the primary key of the current user to the author_id field of requesting data through attribute assignment, and then call the save method of the Schema instance, which will save the data to the database. And assign the primary key value of the new record to the pk attribute of the Schema instance
bulk_save - Save data in batch¶
Schema.bulk_save(data) will save a list of objects in batch. Each element in the list should be a Schema instance or dictionary data conforming to the Schema declaration. This method will perform batch creation or batch update according to the data.
The following is an example of an API for creating users in bulk
from utilmeta.core import api, orm, request
from .models import User
class UserSchema(orm.Schema[User]):
username: str
class UserAPI(api.API):
@api.post
async def bulk(self, data: List[UserSchema] = request.Body) -> List[UserSchema]:
return await UserSchema.abulk_save(data)
from utilmeta.core import api, orm, request
from .models import User
class UserSchema(orm.Schema[User]):
username: str
class UserAPI(api.API):
@api.post
def bulk(self, data: List[UserSchema] = request.Body) -> List[UserSchema]:
return UserSchema.bulk_save(data)
The method in the example uses List[UserSchema] to annotate the body of the request, indicating that it accepts a list of JSON data. The API will automatically parse and convert it into a list of UserSchema instances. You only need to call the UserSchema.bulk_save method to create or update the data in this list in batches.
bulk_save will returns the saved Schema instances list, set the primary key value for the newly created instance. In the above example, we directly returned the result of bulk_save as the API response data.
Apart from the first parameter that takes a list to save, bulk_save provided other parameters to control its save behaviour:
must_create: If set to True, all the items of the list are forced to be created, although an error is thrown if the data contains a primary key that has already been created.must_update: If set to True, all the items of the list are forced to be updated, and an error is thrown when the update cannot be completed, such as when the primary key is missing or does not exist.transaction: you can set to True or a database connection name to enable the transaction for that database, default is False, set to True will enable transaction for the default database of the corresponding modelusing: Set a database connection name to specify the database to save, by default will be the default database of the corresponding model (defaultin Django ORM)
commit - Update the queryset¶
A orm.Schema Instance can call commit(queryset) to batch update the data in it to all records covered by the queryset
Asynchronous methods¶
When you call the asynchronous method of orm.Schema, for example ainit asave aserialize, UtilMeta will implement the asynchronous query. Generally speaking, in the asynchronous API function, you should use orm.Schema's async method, such as
class ArticleAPI(api.API):
async def get(self, id: int) -> ArticleSchema:
return await ArticleSchema.ainit(id)
But even if you call a synchronous method in an asynchronous function, such as
class ArticleAPI(api.API):
async def get(self, id: int) -> ArticleSchema:
return ArticleSchema.init(id)
The endpoint in the example can still process requests normally, but because Django’s native query engine does not support direct execution in an asynchronous environment, synchronous queries in the asynchronous API are processed by a thread in the threadpool.
Although UtilMeta’s declarative ORM will automatically adjust the execution strategy based on the asynchronous environment and ORM engine, if you use Django’s synchronous method query directly in the asynchronous function, there will be errors, such as
class ArticleAPI(api.API):
@api.get
async def exists(self, id: int) -> bool:
return Article.objects.filter(id=id).exists()
You will get the following errors
SynchronousOnlyOperation: You cannot call this from an async context
- use a thread or sync_to_async.
Because Django’s synchronous query methods use a query engine that is strictly dependent on the current thread, you should use their asynchronous variants (prepended a to the method name).
class ArticleAPI(api.API):
@api.get
async def exists(self, id: int) -> bool:
return await Article.objects.filter(id=id).aexists()
Relational query¶
It is a very common API requirement to return the data of relational objects when querying. For example, the corresponding author data is required when returning articles, and the corresponding product information is required when returning purchase orders. These can be collectively referred to as relational queries. UtilMeta’s declarative ORM can handle such queries very concisely. The corresponding usage is described in detail below.
Relation field¶
You can query only a single field of a relational object, and the way to declare it is very simple, as follows.
class ArticleSchema(orm.Schema[Article]):
author_name: str = orm.Field('author.username')
In the example, author_name declared 'author.username' as the value of the query field to query the username field of the author field of the aritlce
In addition to foreign keys, you can also query a single field in a multi relationship, but you need to use a list type to wrap the element type, as shown in
class ArticleSchema(orm.Schema[Article]):
tag_list: List[str] = orm.Field('tags.name')
The Article model has a many-to-many relationship named 'tags' pointing to a Tag model with name fields, so you can use 'tags.name' to serialize the name fields of all the tags related to the article into a list of strings.
Of course, if you use orm.Field('tags') to query the primary keys of all the related tags.
Relation object¶
The common way of relational query is to serialize the entire related object according to a certain structure, such as the article-author ( author) field in the above example. The way to query the relational object is very simple, just annotate the expected query structure in orm.Schema as the type of the relational field.
For a foreign key field, there is only one relationship object, so you can specify the Schema class directly, such as
from utilmeta.core import orm
from .models import User, Article
from django.db import models
class UserSchema(orm.Schema[User]):
username: str
articles_num: int = models.Count('articles')
class ArticleSchema(orm.Schema[Article]):
id: int
author: UserSchema
content: str
author field of ArticleSchema directly specifies UserSchema as the type annotation, which will serialize the author user object into a UserSchema instance.
Use Optional
If the relation object you are querying may be None, (if the field declared null=True), you should use Optional[Schema] as its corresponding type annotation
For Many-to-many/one-to-many fields that may contain multiple relational objects, you should use List[Schema] as the type annotation, such as
from utilmeta.core import api, orm
from .models import User, Article
from django.db import models
class ArticleSchema(orm.Schema[Article]):
id: int
author_name: str = orm.Field('author.username')
content: str
class UserSchema(orm.Schema[User]):
username: str
articles: List[ArticleSchema]
The articles field in UserSchema specified List[ArticleSchema] as a type annotation, and when serialized, the articles field will gets a list of all articles authored by the user (or an empty list if there is no articles).
Prevent N + 1 problems automatically
The N+1 problem is that when you use loops for querying relationships, without special optimization, you may make database queries equivalent to the number of loops (length of queryset) +1, which will greatly affect performance, such as the following code
for user in user_queryset:
articles = Article.objects.filter(author=user).values()
Custom queryset¶
For queries of multiple relational objects, we sometimes need to customize filtering or sorting of the relational object list. In this case, you can use the queryset parameter of orm.Field to specifies a queryset directly, the following example will query each user of a list of articles with the highest number of likes:
from utilmeta.core import api, orm
from .models import User, Article
from django.db import models
class ArticleSchema(orm.Schema[Article]):
id: int
author_name: str = orm.Field('author.username')
content: str
class UserSchema(orm.Schema[User]):
username: str
most_liked_articles: List[ArticleSchema] = orm.Field(
'articles',
queryset=Article.objects.annotate(
likes_num=models.Count('liked_bys')
).filter(
likes_num__gt=0
).order_by('-likes_num')
)
In the above example, use use queryset parameter to specify a custom queryset for most_liked_articles to filter out articles with no likes and sort by likes num
The pre-condition for queryset parameter is to specify a Multiple Relation Name, you can use the first parameter of orm.Field (like 'articles' in the above example) or the attribute name to specify,
No Slicing
Please DO NOT slice the specified queryset (such as limiting the number of returned results), because in order to optimize N+1 query problems, The query implementation of queryset is to query all relational objects at once and distribute them according to their corresponding relationships. If you slice the queryset, the list of relational objects assigned to the queried instances may be incomplete. If you need to implement a requirement similar to "querying up to N relational objects per instance", please refer to the relational query function below.
Single relationship object¶
when you only need to query 1 of the target relational object, you can directly declare the queryset, and UtilMeta will process it into a subquery to compress it into a single query, such as
class ArticleSchema(orm.Schema[Article]):
id: int
content: str
class UserSchema(orm.Schema[User]):
username: str
top_article: Optional[ArticleSchema] = orm.Field(
Article.objects.annotate(
favorites_num=models.Count('favorited_bys')
).filter(
author_id=models.OuterRef('pk')
).order_by('-favorites_num')[:1]
)
OuterRef
Django uses OuterRef to reference the outer fields, in the example, we referenced the primary key of the target User model
Relational query function¶
Relational query function provides a hook that can be customized. You can write any condition for the relational query, such as adding filter and sort conditions, controlling the quantity, etc. The relational query function can be declared in the following ways
Let’s take a requirement as an example. Suppose we need to query a list of users, in which each user needs to attach “Followers the current request user knows”, which is a common requirement in social media such as Twitter (X). so the requirement can be simply and efficiently implemented by using the primary key list function.
from utilmeta.core import orm, request
class UserSchema(orm.Schema[User]):
username: str
@classmethod
def get_followers_you_known(cls, *pks, user_id: int = request.var.user_id):
mp = {}
for val in User.objects.filter(
followings__in=pks,
followers=user_id
).values('followings', 'pk').using(db_using):
mp.setdefault(val['followings'], []).append(val['pk'])
return mp
followers_you_known: List[UserBase] = orm.Field(
get_followers_you_known,
default_factory=list
)
In the example, UserSchema defines a class function that generate different queries for different requesting users, in which we define a get_followers_you_known query function that accepts a list of queried primary keys of current Schema instances and constructs a dict that map each key with a primary key list of the target relationship (Followers you known). After this dictionary is returned, UtilMeta will complete the subsequent aggregate query and result distribution. Finally, the followers_you_known field of each user Schema instance will contain the query results that meet the condition requirement
Tip
Query function can use properties of request.var as the request context variables, such as:
request.var.user_id:Current request user ID,
request.var.user: Current request user instance,
request.var.ip: Current request IP address.
You can pass the current request object (self.request of API) as the context param of the init / serialize method, such as UserSchema.init(1, context=self.request) to query the context fields
Value query function¶
Above, we introduced the relational query function, which needs to correspond the primary key of the currently queried data with the primary key of the related model for the target field, and then serialize it using the relational model schema defined by the field.
However, if we do not need further serialization and directly output the results from the query function, we only need to complete the correspondence between the primary key and field values, this function will called value query function, as shown in the following example
from .models import User, Article
class UserQuerySchema(orm.Schema[User]):
id: int
username: str
@classmethod
def get_article_tags(cls, *pks):
mp = {}
for tags, author_id in Article.objects.filter(
author__in=pks,
).values_list('tags', 'author_id'):
mp.setdefault(author_id, set()).update(tags or [])
return mp
article_tags: Set[str] = orm.Field(get_article_tags)
In this example, the articles tags we defined do not directly correspond to the model fields or related schema. Instead, we use the get_article_tags function to map the the article author with all the tags of the author's articles, and we can get the complete set of article tags for each author.
get_article_tags is a value query function, which is a convenient and efficient way to organize query code. For example, the above example uses a single query to complete the query of article tags for any number of users.
Query Expression¶
Aggregation or calculation of a relational field is also a common development requirement, such as
- Query how many followers or followed people a user has
- Find out how many people liked, viewed and commented on the article
- Get how many orders there are for the product
Almost all models with relational fields require a query for the number of related objects. For Django ORM, you can use models.Count('<relation_name>') to query the number of relations, such as in the example above.
from utilmeta.core import orm
from .models import User
from django.db import models
class UserSchema(orm.Schema[User]):
username: str
articles_num: int = models.Count('articles')
The articles_num field of UserSchema is using models.Count('articles') to indicate the number of 'articles' relationships, which is how many articles a user has created.
Beside quantities, expression queries can be used for some common data calculations, such as
models.Avg: Average calculation, such as calculating the average rating of a store or productmodels.Sum: Summation calculation, such as calculating the total sales of a commodity.models.Max: Maximum value calculationmodels.Min: Minimum value calculation
Query expressions can used as the attribute value directly, or passed as the first parameter of orm.Field to configure more field settings, for example:
from utilmeta.core import orm
from .models import User
from django.db import models
class UserSchema(orm.Schema[User]):
username: str
articles_num: int = orm.Field(
models.Count('articles'),
title='Articles Count',
default=0
)
Here are some expressions that are commonly used in real-world development
Exists¶
Sometimes you need to return the field of whether a conditional queryset exists, for example, when querying a user, you can use Exists an expression to return "whether the current request user has followed".
from utilmeta.core import orm
from django.db import models
class UserSchema(orm.Schema[User]):
username: str
@classmethod
def get_followed(cls, user_id: int = request.var.user_id):
return models.Exists(
User.objects.filter(
pk=user_id,
followers=exp.OuterRef('pk')
)
)
followed: bool = orm.Field(get_followed, default=False)
SubqueryCount¶
For some relation counts you may need to add some conditions, for example, when querying an article, you need to return "how many of the current user’s followings liked the article", in which case you can use SubqueryCount expressions.
from utilmeta.core import orm, request
from utilmeta.core.orm.backends.django import expressions as exp
class ArticleSchema(orm.Schema[Article]):
id: int
content: str
@classmethod
def get_following_likes(cls, user_id: int = request.var.user_id):
return exp.SubqueryCount(
User.objects.filter(
followers=user_id,
likes=exp.OuterRef('pk')
)
)
following_likes: int = orm.Field(get_following_likes, default_factory=list)
Tip
More usage of django query expressions can refer to Django aggregations
orm.Schema usage¶
This section will introduce more usages of orm.Schema
orm.Field parameters¶
Each field declared in orm.Schema can specifies orm.Field(...) as a property value to configure the behavior of the field. Common field configuration parameters are
The first parameter field. When the field you want to query is not in the current model (cannot be directly represented as the attribute name of Schema class), you can use this parameter to specify the field value you want to query. The above example has shown the relevant usage, such as
- Pass in a relational query field, such as
orm.Field('author.username') - Pass in a relational query function, such as
orm.Field(get_top_comments) - Pass in a queryset
- Pass in a query expression, such as
orm.Field(models.Count('articles'))
In addition to the first parameter, you can use the following parameters to implement more field behaviors
no_input: Set to True to ignore the field input. For example, when creating an article, the fieldauthor_idshould not be provided by the request data, but should be assigned to the user ID of the current request in the API function, so it needs to be declared.no_output: Set to True to discard the field output. For example, when creating an article, the request data can be required to contain a list of tags, but it does not need to be saved in the article model instance, so it can be declared.mode: You can specify a mode for a field so that the field only works in the corresponding mode. In this way, you can use a single Schema class to handle various scenarios like query, create, update, etc. The Realworld Blog Project shows the detailed examples of this usage.
field parameter configuration
orm.Field inherits from utype.Field, so the detailed usage can refer to utype- Field configuration
@property field¶
You can use the @property of Schema class to quickly develop fields that are calculated based on the query result data, such as
from datetime import datetime
class UserSchema(orm.Schema[User]):
username: str
signup_time: datetime
@property
def joined_days(self) -> int:
return int((datetime.now() - self.signup_time).total_seconds() / (3600 * 24))
In the example, the joined_days property calculates the number of days the user has registered through the user’s signup time and outputs it as the value of the field.
Schema Inheritance¶
orm.Schema Classes can also reuse declared fields using class inheritance, for example,
from utilmeta.core import orm
from .models import User
class UsernameMixin(orm.Schema[User]):
username: str = orm.Field(regex='[A-Za-z0-9_]{1,20}')
class UserBase(UsernameMixin):
bio: str
image: str
class UserLogin(orm.Schema[User]):
email: str
password: str
class UserRegister(UserLogin, UsernameMixin): pass
In the example we defined
UsernameMixin: contains onlyusernamefield, which can be reused by other Schema classesUserBase: Inherit UsernameMixin and defines the basic information of the userUserLogin: Parameters required for user loginUserRegister: Parameters required for user registration, which is the combination of theUserLoginandUsernameMixin.
All of the above Schema classes can be used and queried independently
Model inheritance¶
Django models can reuse model fields using class inheritance, such as
from django.db import models
class BaseContent(models.Model):
body = models.TextField()
created_at = models.DateTimeField(auto_now_add=True)
updated_at = models.DateTimeField(auto_now=True)
class Meta:
abstract = True
class Article(BaseContent):
slug = models.SlugField(db_index=True, max_length=255, unique=True)
title = models.CharField(db_index=True, max_length=255)
description = models.TextField()
author = models.ForeignKey('user.User', on_delete=models.CASCADE, related_name='articles')
tags = models.ManyToManyField(Tag, related_name='articles')
class Comment(BaseContent):
article = models.ForeignKey(Article, related_name='comments', on_delete=models.CASCADE)
author = models.ForeignKey('user.User', on_delete=models.CASCADE, related_name='comments')
In the above example, the repeated fields in the Article and Comment model are integrated into the BaseContent abstract model. Similar techniques can be used to reuse fields in the ORM Schema class. For the Schema base class, you can declare without the model. Inject at inheritance time, such as
from utype.types import *
from utilmeta.core import orm
from domain.user.schema import UserSchema
from .models import Comment, Article
class ContentSchema(orm.Schema):
body: str
created_at: datetime
updated_at: datetime
author: UserSchema
author_id: int = orm.Field(mode='a', no_input=True)
class CommentSchema(ContentSchema[Comment]):
id: int = orm.Field(mode='r')
article_id: int = orm.Field(mode='a', no_input=True)
class ArticleSchema(ContentSchema[Article]):
id: int = orm.Field(no_input=True)
slug: str = orm.Field(no_input='aw', default=None, defer_default=True)
title: str = orm.Field(default='', defer_default=True)
description: str = orm.Field(default='', defer_default=True)
In the example, we defined the ContentSchema base class, which hosts the common data structure in articles and comments, but does not inject the model. CommentSchema and ArticleSchema declared later inherit from it and inject the corresponding model.
Warning
orm.Schema without models cannot be used in queries, such as ContentSchema in the example
orm.Query parameters¶
UtilMeta’s declarative ORM also supports parsing query parameters to generate queryset, such as filter conditions, sorting, quantity control, etc. The following is a simple example. You can directly add ID and author filter to the query API of the article.
from utilmeta.core import orm
class ArticleQuery(orm.Query[Article]):
id: int
author_id: int
class ArticleAPI(api.API):
async def get(self, query: ArticleQuery) -> List[ArticleSchema]:
return await ArticleSchema.aserialize(query)
from utilmeta.core import orm
class ArticleQuery(orm.Query[Article]):
id: int
author_id: int
class ArticleAPI(api.API):
def get(self, query: ArticleQuery) -> List[ArticleSchema]:
return ArticleSchema.serialize(query)
We use orm.Query[<model>] to declare the query parameters of a model, and the declared Query class will be automatically processed as the query parameters of the request ( request.Query) when it is used in the type annotation of API function parameters. You can pass an instance of it directly to orm.Schema's serialize method in a function to serialize the corresponding query result.
Filter params¶
if the field declared in orm.Query has the same name in the model, will be automatically processed as a filter parameter. When the request provides this filter parameter, the corresponding condition will be added to the target query. For example, when request GET /article?author_id=1, You’ll get a set of article queries with author_id=1 condition.
When you need to define more complex query parameters, you need to use orm.Filter component. Here is an example of its common usage.
from utilmeta.core import orm
from datetime import datetime
from django.db import models
class ArticleQuery(orm.Query[Article]):
author: str = orm.Filter('author.username')
keyword: str = orm.Filter('content__icontains')
favorites_num: int = orm.Filter(models.Count('favorited_bys'))
within_days: int = orm.Filter(query=lambda v: models.Q(
created_at__gte=datetime.now() - timedelta(days=v)
))
class ArticleAPI(api.API):
def get(self, query: ArticleQuery) -> List[ArticleSchema]:
return ArticleSchema.serialize(query)
The first parameter of orm.Filter can specify the name of the query field, and several kinds are shown in the example.
author: Query the relation field'author.username', which is the username of the author userkeyword: Query the fieldcontentthat case-insensitively contains (icontains) the target parameter, thus be a simple search featurefavorites_num: Query a relational count expressionmodels.Count('favorited_bys'), which is the number of likes.
In addition, you can specify a query expression with the query parameter of orm.Filter , receive a parameter (which is the corresponding query parameter value in the request), and return a query expression, which should be an models.Q expression in Django. It can contain custom query conditions, such as the within_days query in the example of articles within a few days of creation.
Tip
For more lookups (to construct WHERE of SQL) in Django, you can refer to Django Field Lookups
orm.Filter also inherits from utype.Field, so other field configurations are still valid, such as
required: Required. The default fororm.Filterisrequired=False, which means it is a optional parameter. The corresponding query condition will be applied only when it is provided.default: Specify default values for query parameteralias: Specify an alias for the query parameter
Search Param¶
A commonly used type of query parameter is used to search for fuzzy matching of one or more fields of the target. Such search parameter can be defined using the orm.Search in UtilMeta, such as
from utilmeta.core import orm
from datetime import datetime
from django.db import models
class ArticleQuery(orm.Query[Article]):
search: str = orm.Search(
Article.title,
Article.content,
Article.slug,
Article.tags
)
class ArticleAPI(api.API):
def get(self, query: ArticleQuery) -> List[ArticleSchema]:
return ArticleSchema.serialize(query)
orm.Search can receive strings or a field references of model that can be used for searching (usually text strings containing the main information of the model, such as title, summary, description, etc.), in addition, there are some search settings that can be specified:
case_sensitive: Whether to search case sensitively, default to Falsekeyword_delimiters: Specify the delimiter for keywords. the search text will be divided into keywords first, and then the fields will be queried and matched. The default is(' ', ',', ';', '|')match_mode: Match mode for field and keywords, includes:orm.Search.ANY_ANY: Match any field with any keyword for the most relaxed searchorm.Search.UNION_ALL: The searchable fields of the instance can match all keywords (which can be divided into any one or more fields)orm.Search.ANY_ALL: Any single searchable field needs to match all keywords, defaultorm.Search.ALL_ALL: All fields need to match all keywords, the strictest search
Note
UtilMeta >= 2.8.0 支持 orm.Search 搜索参数
Sorting params¶
You can also declare sorting parameter in orm.Query class. with the supported sorting fields and the corresponding configuration. Examples are as follows
from utilmeta.core import orm
from django.db import models
from .models import Article
class ArticleQuery(orm.Query[Article]):
order: List[str] = orm.OrderBy({
"comments_num": orm.Order(field=models.Count("comments")),
"favorited_num": orm.Order(field=models.Count("favorited_bys")),
Article.created_at: orm.Order(),
})
class ArticleAPI(api.API):
def get(self, query: ArticleQuery) -> List[ArticleSchema]:
return ArticleSchema.serialize(query)
The sort parameter use orm.OrderBy to define, in which a dictionary that declares the sort option. The key of the dictionary is the name of the sort option, and the value is the configuration.
After the sort parameter is declared, the client can pass in a list of sort options. The sort options are selected from the declaration of the sort parameter. You can add - a (minus) before the options to indicate that they are sorted in descending order. for the above example, when the client requests GET /article?order=-favorited_num,created_at, the detected sort options are
-favorited_num: Sort in reverse order of the number of likes. the more likes an article got, the prior it rankcreated_at: Sorted in the order of creation time, the earlier, the prior
Each of the sort options can configure using orm.Order. The supported parameters are
field: The sorting target field or expression can be specified. If the name of the corresponding sorting option is the name of the model field, it can left empty (such as increated_atthe example).asc: Whether ascending order is supported. The default value is True. If it is set to False, ascending order is not supported.desc: Whether descending order is supported. The default value is True. If it is set to False, descending order is not supported.document: Specify a documentation string for the sort field that will be integrated into the API documentation.
In sorting, there is a kind of value that is more difficult to handle, the null value. The behaviour of null value if sorting is determined by the following parameters
notnull: Whether to filter out the null value instances of this field. The default is False.nulls_first: sort the null value instances to be the first (first in ascending order, last in descending order)nulls_last: sort the null value instances to be the last (last in ascending order, first in descending order)
If none of these parameters are specified, the sorting of null value instances will be determined by the database
Paging params¶
In actual development, we are unlikely to return hundreds of records by the query at one time. Instead, we need to provide Paging control mechanism. orm.Query class also supports defining several preset paging parameters so that you can quickly implement the paging query API. The following is an example.
from utilmeta.core import orm
from django.db import models
from .models import Article
class ArticleQuery(orm.Query[Article]):
offset: int = orm.Offset(default=0)
limit: int = orm.Limit(default=20, le=100)
class ArticleAPI(api.API):
def get(self, query: ArticleQuery) -> List[ArticleSchema]:
return ArticleSchema.serialize(query)
The two paging control parameters defined in the example are as follow
offset: Specify aorm.Offsetfield to control the starting offset of the query. For example, if the client has queried 30 results, the next request will be sent?offset=30to query the results after 30.limit: Specify aorm.Limitfield to control the limit of the number of results returned by the query. The default value is 20, thus the number of results returned is limited to 20 when this parameter is not provided, and the maximum value is 100, so the parameter cannot be greater than this value.
For example, when the client requests GET /article?offset=10&limit=30, it will return 10 to 40 of the query results.
In addition to the offset / limit mode, there is another way for the client to pass the “number of pages” of the page directly, such as
from utilmeta.core import orm
from django.db import models
from .models import Article
class ArticleQuery(orm.Query[Article]):
page: int = orm.Page()
rows: int = orm.Limit(default=20, le=100)
class ArticleAPI(api.API):
def get(self, query: ArticleQuery) -> List[ArticleSchema]:
return ArticleSchema.serialize(query)
The page parameter in the example specifies a orm.Page field, which exactly corresponds to the concept of the number of pages in the frontend, and starts counting from 1. For example, when the client requests GET /article?page=2&rows=10, it will return 10 to 20 items in the query results, which is “Page 2“ in the client data.
count() Total number of results¶
In order for the client to display the total number of pages queried, we often need to return the total number of results queried (while ignoring the paging parameter). To implement this requirement, orm.Query instance provides a count() method, with the asynchronous variant acount()
The following demonstrates how the article pagination API for a blog project is handled
from utilmeta.core import orm, api, response
class ArticlesResponse(response.Response):
result_key = 'result'
count_key = 'count'
result: List[ArticleSchema]
class ArticleAPI(api.API):
class ListArticleQuery(orm.Query[Article]):
author: str = orm.Filter('author.username')
offset: int = orm.Offset(default=0)
limit: int = orm.Limit(default=20, le=100)
async def get(self, query: ListArticleQuery) -> ArticlesResponse:
return ArticlesResponse(
result=await ArticleSchema.aserialize(query),
count=await query.acount()
)
from utilmeta.core import orm, api, response
class ArticlesResponse(response.Response):
result_key = 'result'
count_key = 'count'
result: List[ArticleSchema]
class ArticleAPI(api.API):
class ListArticleQuery(orm.Query[Article]):
author: str = orm.Filter('author.username')
offset: int = orm.Offset(default=0)
limit: int = orm.Limit(default=20, le=100)
def get(self, query: ListArticleQuery) -> ArticlesResponse:
return ArticlesResponse(
result=ArticleSchema.serialize(query),
count=query.count()
)
In the example, we use the response template to define a nested data structure, including the query result ( result) and the total number of queries ( count ), the list data serialized using ArticleSchema are passed to the result, while the total number of results from query.count() passed to the count
When the client receives the count value, it can calculate the total number of pages displayed.
let pages = Math.ceil(count / rows_per_page)
Field Control Params¶
UtilMeta also provides a result field control mechanism similar to GraphQL, which allows the client to select which fields to return or which fields to exclude, so as to further optimize the query efficiency of the API, examples are as follows
from utilmeta.core import orm
from .models import User, Article
from django.db import models
from datetime import datetime
class UserSchema(orm.Schema[User]):
username: str
articles_num: int = models.Count('articles')
class ArticleSchema(orm.Schema[Article]):
id: int
author: UserSchema
content: str
created_at: datetime
favorites_count: int = models.Count('favorited_bys')
class ArticleQuery(orm.Query[Article]):
scope: List[str] = orm.Scope()
exclude: List[str] = orm.Scope(excluded=True)
class ArticleAPI(api.API):
def get(self, query: ArticleQuery) -> List[ArticleSchema]:
return ArticleSchema.serialize(query)
In ArticleQuery, we define a orm.Scope parameter named scope, which can be used by the client to specify a list of fields, so that the result only returns the fields in the list. For example, the request GET /article?scope=id,content,created_at will only return id, content and created_at field
Another exclude parameter is also used orm.Scope, but it is specified excluded=True, which means that the field given in the parameter will be excluded, and the request GET/article?exclude=author will return the result data without the author field.
Note
Reasonable usage of orm.Scope parameters by the client can not only reduce bandwidth consumption, but also reduce corresponding query pressure, because the UtilMeta framework will trim the generated query statements based on the fields specified in the scope parameter, only querying the fields that need to be included in the result. if the query consumption of certain fields is high (such as complex nested multi pair relationship objects or expression queries), When these fields are not included in the expected result field, query processing will not be performed
get_queryset¶
For orm.Query instance, in addition to being serialized directly to a method such as Schema.serialize, you can also call its get_queryset method to get the generated queryset, such as a Django QuerySet for a Django model.
get_queryset can also accept a base queryset parameter, and add the filtering, sorting, and paging based on the base queryset.
class ArticleAPI(API):
class ListArticleQuery(orm.Query[Article]):
author: str = orm.Filter('author.username', required=True)
offset: int = orm.Offset(default=0)
limit: int = orm.Limit(default=20, le=100)
scope: dict = orm.Scope()
@api.get
async def list(self, query: ListArticleQuery):
return await ArticleSchema.aserialize(
queryset=query.get_queryset(
Article.objects.exclude(comments=None)
),
context=query.get_context()
)
In the example, we use query.get_queryset method to get the queryset generated by the query parameters, and pass in a custom base QuerySet, and pass the result of the generated queryset to the queryset parameter of the serialize method.
Tip
The scope parameters are special params that won't affect queryset, but will affect the output fields, which should pass through query.get_context()
Database and ORM configuration¶
We have introduced the usage of UtilMeta declarative ORM, but if you need to connect to the database to use it, you need to complete the configuration of the database and ORM.
As a meta-framework, UtilMeta’s declarative ORM is able to support a range of ORM engines implemented as a model layer. The current support status is
- Django ORM:Fully supported
- Tortoise-orm: Upcoming support
- Peewee: Upcoming support
- SQLAchemy: Upcoming support
So let’s take Django ORM as an example of how to configure database connections and models.
First assume that your project is created using the following command
meta setup blog --temp=full
The folder structure is similar
/blog
/config
conf.py
service.py
/domain
/article
models.py
/user
models.py
/service
api.py
main.py
meta.ini
You can configure the following code in config/conf.py
from utilmeta import UtilMeta
from config.env import env
def configure(service: UtilMeta):
from utilmeta.core.server.backends.django import DjangoSettings
from utilmeta.core.orm import DatabaseConnections, Database
service.use(DjangoSettings(
apps_package='domain',
secret_key=env.DJANGO_SECRET_KEY
))
service.use(DatabaseConnections({
'default': Database(
name='db',
engine='sqlite3',
)
}))
service.setup()
from utilmeta import UtilMeta
from config.conf import configure
from config.env import env
import starlette
service = UtilMeta(
__name__,
name='blog',
backend=starlette,
production=env.PRODUCTION,
)
configure(service)
We define the configure function in config/conf.py to configure the service, receive the UtilMeta service instance, and use use() method to configure it.
To use Django ORM, you need to use the configuration of Django. UtilMeta provides DjangoSettings as an easy way to configure Django. The important parameters are
apps_package: Specify a directory in which each folder will be treated as a Django App, and Django will scan themodels.pyfiles in it to detect all models, such as'domain'folder in the example.apps: You can also specify a list of Django app references to list all model directories, such as['domain.article', 'domain.user']secret_key: Specify a key, which you can manage using environment variables.
Database connection¶
In UtilMeta, you can use DatabaseConnections to configure the database connection, where you can pass in a dictionary. The key of the dictionary is the name of the database connection. We use the syntax of Django to define the database connection, and use 'default' to represent the default connection. The corresponding value is an Database instance that is used to configure a specific database connection, and the parameters include
name: name of the database (in SQLite3, the name of the database file)engine: database engine, Django ORM supported engines aresqlite3,mysql,postgresql,oracleuser: username of the databasepassword: user's password for the databasehost: host of the database, localhost by default (127.0.0.1)port: port number of the database, if not specified, will determined by the database, such as 3306 formysqland 5432 forpostgresql
SQLite3
The database in the example uses SQLite3 as the engine, you don't need to provide user, password and host, it will create a file named the name param you specified to store the data, which is suitable for quick debugging in the development stage.
PostgreSQL / MySQL
When you need to use PostgreSQL or MySQL connections that require a database password, we recommend that you use environment variables to manage this sensitive information. Examples are as follows
from utilmeta import UtilMeta
from config.env import env
def configure(service: UtilMeta):
from utilmeta.core.server.backends.django import DjangoSettings
from utilmeta.core.orm import DatabaseConnections, Database
service.use(DjangoSettings(
apps_package='domain',
secret_key=env.DJANGO_SECRET_KEY
))
service.use(DatabaseConnections({
'default': Database(
name='blog',
engine='postgresql',
host=env.DB_HOST,
user=env.DB_USER,
password=env.DB_PASSWORD,
port=env.DB_PORT,
)
}))
service.setup()
from utilmeta.conf import Env
class ServiceEnvironment(Env):
PRODUCTION: bool = False
DJANGO_SECRET_KEY: str = ''
DB_HOST: str = '127.0.0.1'
DB_PORT: int = None
DB_USER: str
DB_PASSWORD: str
env = ServiceEnvironment(sys_env='BLOG_')
In config/env.py, we declare the key information required for the configuration and pass sys_env='BLOG_' it in the initialization parameter, which means that the system environment variable with the prefix BLOG_ will be collected, so you can specify an environment variable like
BLOG_PRODUCTION=true
BLOG_DJANGO_SECRET_KEY=your_key
BLOG_DB_USER=your_user
BLOG_DB_PASSOWRD=your_password
After initialization env, it will parse the environment variables to the corresponding type and attributes, and you can use them directly in the configuration file.
Django Migration¶
When we have written the data models, we can use the migration command provided by Django to easily create the corresponding data table. If you use SQLite, you do not need to install the database software in advance. Otherwise, you need to install PostgreSQL or MySQL database to your computer or online environment first. Then create a database with the same name as your connection. After the database is ready, you can use the following command to complete the data migration.
meta makemigrations
meta migrate
Migration is successful when you see the following output
Operations to perform:
Apply all migrations: article, contenttypes, user
Running migrations:
Applying article.0001_initial... OK
Applying user.0001_initial... OK
Applying article.0002_initial... OK
Applying contenttypes.0001_initial... OK
Applying contenttypes.0002_remove_content_type_name... OK
For SQLite database, the corresponding database files and data tables will be created directly, while for other databases, the corresponding data tables will be created according to your model definition
Database Migration Commands
The above command is the migration commands of Django, makemigrations will save your migrations of models into files, while migrate applied the unapplied migration files to SQLs that create or alter tables.
Asynchronous query¶
Asynchronous queries do not require additional configuration, but depend on how you call them. If you use orm.Schema asynchronous methods such as ainit, aserialize asave, etc., then the implementation of asynchronous queries will be called internally.
Each method in Django ORM also has a corresponding asynchronous implementation, but in fact it only uses sync_to_async methods to turn the synchronous function into an asynchronous function as a whole, and its internal query logic and driver implementation are still all synchronous and blocking.
AwaitableModel
UtilMeta ORM implement a pure asynchronous version of all methods in Django ORM, and uses encode/databases library as the asynchronous driver of each database engine to maximize the performance of asynchronous queries. The model base class hosting this implementation is located in
from utilmeta.core.orm.backends.django.models import AwaitableModel
If your Django models inherit from AwaitableModel, all of its ORM methods will be implemented completely asynchronously.
!!! warning “ACASCADE”
When you are using the on_delete option in AwaitableModel, if you choose the cascade delete feature, you should use utilmeta.core.orm.backends.django.models.ACASCADE, which is the async version of django.db.models.CASCADE
In fact, encode/databases also integrates the following asynchronous query drivers respectively
So if you need to specify the asynchronous query engine when you select the database, you can pass it in the engine parameter like sqlite3+aiosqlite. postgresql+asyncpg
Transaction plugin¶
Transaction is also a very important mechanism for data query and operations, which guarantees the atomicity of a series of operations (either overall success or overall failure with no effects).
In UtilMeta, you can use orm.Atomic as an API decorator to enable database transactions for an endpoint, and we have shown the corresponding usage in the example of the creation API of the article.
from utilmeta.core import orm
class ArticleAPI(API):
@orm.Atomic('default')
async def post(self, article: ArticleSchema[orm.A] = request.Body,
user: User = API.user_config):
tags = []
for name in article.tag_list:
tag, created = await Tag.objects.aget_or_create(name=name)
tags.append(tag)
article.author_id = user.pk
await article.asave()
if self.tags:
# create or set tags relation in creation / update
await self.article.tags.aset(self.tags)
The article API in this example needs to complete the creation and relation assignment of tags. We directly use @orm.Atomic('default') on the endpoint function to indicate that the transaction is enabled for the 'default' database connection (corresponding DatabaseConnections to the defined database connection). If this function completes successfully, the transaction is committed, and if any exceptions occur, the transaction is rolled back
So in the example, the article and tags are either created and set successfully at the same time, or failed completely and has no effect on the data of database.