数据查询与 ORM 操作¶
UtilMeta 实现了一套独特高效的声明式 Schema 查询机制来快速实现增删改查操作与开发 RESTful 接口,我们可以在 UtilMeta 框架主页 中看到声明式 ORM 与 API 的简洁案例代码
本篇文档我们将详细说明相应的用法
ORM 概述¶
Web 开发中最常见的需求之一是提供对数据增删改查的 RESTful 接口,而 ORM(Object Relational Mapping,对象关系映射)就是一种常用的把关系数据库中的表和面向对象编程(如 Python 中的类)映射的方式,可以很大程度方便我们开发增删改查接口,相对于 SQL 拼接而言也消除了 SQL 注入的隐患
我们用 Python Web 中比较常见的 Django ORM 来示例如何定义一个简单的博客应用中的用户模型与文章模型
from django.db import models
class User(models.Model):
username = models.CharField(max_length=20, unique=True)
class Article(models.Model):
author = models.ForeignKey(
User, related_name="articles",
on_delete=models.CASCADE
)
content = models.TextField()
- User 模型中声明了
VARCHAR(20)类型的username字段,并且字段的值是不能重复的(unique=True) - Article 模型中声明了名为
author的指向 User 模型外键表示文章的作者,它的反向关系是"articles",即表示一个用户的【所有文章】,当对应的作者用户删除时文章将级联删除(CASCADE)
Tip
关于 Django ORM 的详细用法可以参考 Django ORM 文档,但即使你不了解相关用法,也可以直接继续学习 UtilMeta 的声明式 ORM
本篇文档接下来的声明式 ORM 用法都将基本围绕着 Realworld 博客项目 中的 Django 模型进行演示,如用户,文章,评论,关注等
UtilMeta ORM 声明方式¶
UtilMeta 的声明式 ORM 可以让你预先把期望查询结果的数据结构使用 Schema 类声明出来,然后就可以直接调用这个 Schema 类的方法查询得到你需要的数据了。我们还是使用上面声明的模型示例简单的声明式 ORM 用法
from utilmeta.core import api, orm
from .models import User, Article
from django.db import models
class UserSchema(orm.Schema[User]):
username: str
articles_num: int = models.Count('articles')
class ArticleSchema(orm.Schema[Article]):
id: int
author: UserSchema
content: str
我们在声明 ORM Schema 类时需要使用了 orm.Schema[<model_class>] 的方式将对应的 ORM 模型类注入进去,我们在例子中定义的有
UserSchema:注入了 User 模型,其中定义的字段有
username:对应用户模型的同名字段,将其序列化为str类型articles_num:查询用户的文章数的表达式字段,使用了Count表达式查询文章作者字段的反向关系'articles'
ArticleSchema:注入了 Article 模型,其中定义的字段有
id:主键字段,无论是否在模型中定义,一个表都会具有主键,而主键字段的默认名称就是idauthor:作者字段,将先前定义 UserSchema 作为类型声明,表示将直接把文章对应的作者信息使用 UserSchema 序列化出来作为整个字段的值content:内容字段
如果你在 Schema 类中声明与模型字段同名的属性,那么就会按照声明的类型序列化出对应的字段,对于外键等关系字段,你可以选择只序列化出对应的外键值,也可以指定一个 Schema 类序列化出整个关系对象,还有其他的字段用法我们将在下文逐一介绍
Tip
我们在编写模型对应的 ORM Schema 时,其实思考的是对于这个模型的查询需要得到什么样的结果,或者客户端需要什么样的数据结构,比如对于文章这种 UGC 内容,经常需要把它的作者一起序列化出来并返回,好让客户端直接显示出来(而不是再用 ID 查询一次用户接口),所以例子中的 author 字段返回的是整个用户对象
orm.Schema 的方法¶
我们了解了 orm.Schema 基本的声明方式,下面我们介绍 orm.Schema 类或者实例的重要方法,通过调用这些方法,你就可以完成数据的查询,创建,更新,批量保存等操作
init - 序列化单个对象¶
Schema.init(obj) 方法会把传入的对象参数序列化为 单个 Schema 实例,其中的对象参数可以传入
- ID 值,比如
ArticleSchema.init(1)就是将 ID 为 1 的文章对象序列化为一个 ArticleSchema 实例 - 传入模型对象实例
- 传入一个查询集(QuerySet),这样会将查询集中的 首个 对象序列化为一个 Schema 实例
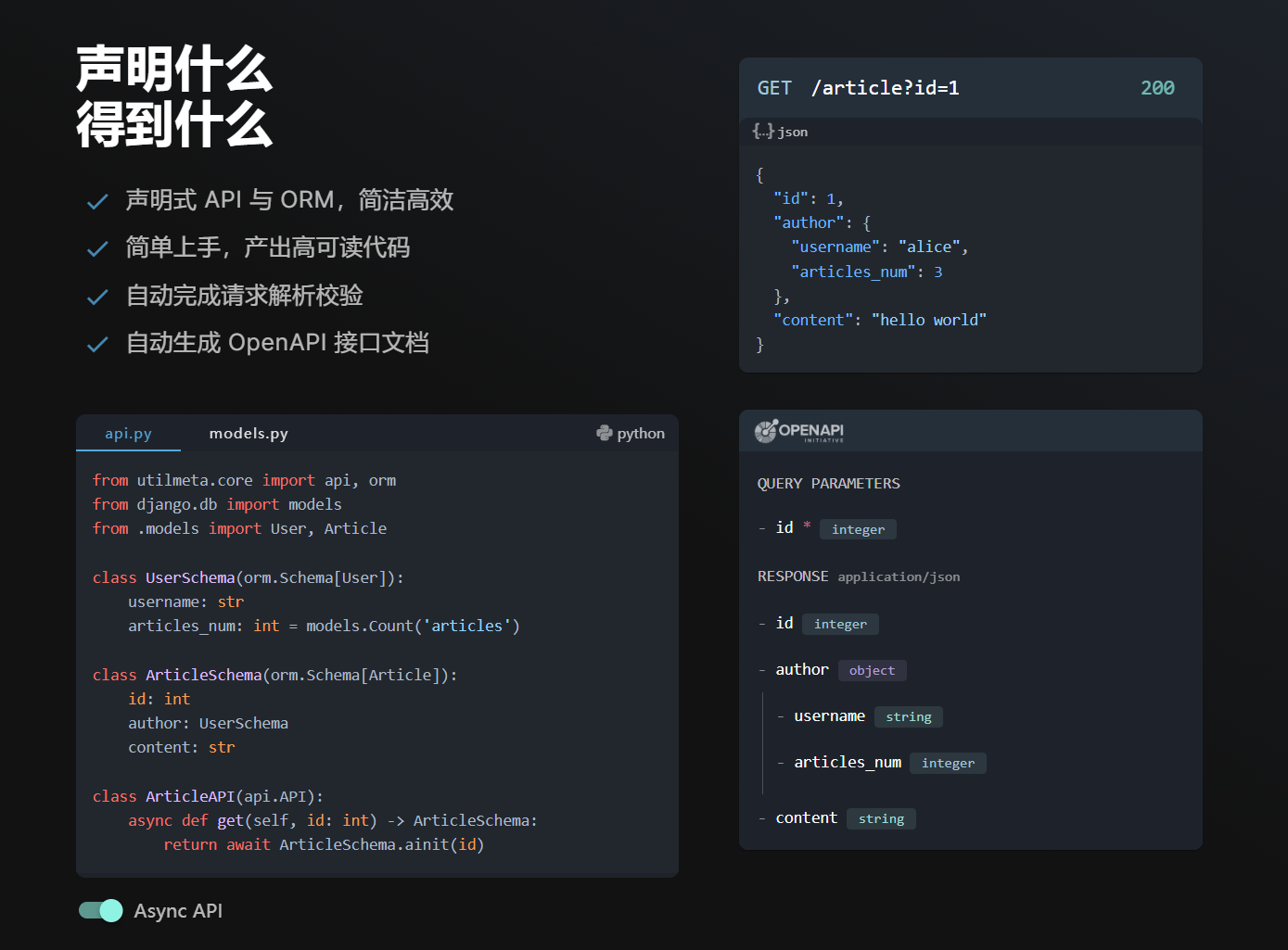
在 UtilMeta 框架主页 中的第一段示例代码就包含了对 init 方法或它的异步变体 ainit 的调用
class ArticleAPI(api.API):
async def get(self, id: int) -> ArticleSchema:
return await ArticleSchema.ainit(id)
class ArticleAPI(api.API):
def get(self, id: int) -> ArticleSchema:
return ArticleSchema.init(id)
例子中的 get 方法直接把请求的 ID 参数传递给 ArticleSchema 的 ainit 方法,就可以直接序列化出 ID 为 1 的文章实例
异步查询方法
orm.Schema 的所有查询方法都有对应的异步方法,只需在方法名前加 a 即可,如 ainit, aserialize, asave ,异步方法只能在 async def (异步函数)中调用,需要使用 await 等待执行完毕
所以如果 ArticleAPI 的路径为 /article,当我们访问 GET /article?id=1 我们就会得到类似如下的 JSON 数据结果
{
"id": 1,
"author": {
"username": "alice",
"articles_num": 3
},
"content": "hello world"
}
这样的结果完全符合 ArticleSchema 的声明,所以声明式 ORM 的核心理念就是【声明什么,得到什么】(What you define is what you get)
serialize - 序列化列表¶
Schema.serialize(queryset) 会将一个查询集(QuerySet)序列化为 Schema 实例的列表,这是很常用的一个序列化方法,当 API 需要返回列表数据时就会用到
当你使用 Django ORM 时,serialize 接受的参数就是一个模型一致的 Django QuerySet,比如对于 ArticleSchema,接受的应该是 Article 模型的 QuerySet,下面是一个示例
class ArticleAPI(API):
@api.get
async def feed(self, user: User = API.user_config,
limit: int = utype.Param(10, ge=0, le=50)) -> List[ArticleSchema]:
return await ArticleSchema.aserialize(
Article.objects.filter(author__followers=user)[:limit]
)
class ArticleAPI(API):
@api.get
def feed(self, user: User = API.user_config,
limit: int = utype.Param(10, ge=0, le=50)) -> List[ArticleSchema]:
return ArticleSchema.serialize(
Article.objects.filter(author__followers=user)[:limit]
)
例子中的 feed 接口会返回当前用户关注的作者发布的文章,我们只需将构造好的 QuerySet 传递给 ArticleSchema.serialize 方法,就会得到一个以 ArticleSchema 实例为元素的列表,最后被 API 接口处理为 JSON 响应给客户端
Tip
例子中如何鉴权与获取当前请求的用户并不是本篇文档的重点,但你可以在 接口与用户鉴权 找到详细的说明
save - 保存数据¶
由一个 orm.Schema 实例调用,将其中的数据保存到模型对应的数据表中,如果 Schema 实例中包含着存在于数据表中的主键,那么会更新对应的表记录,否则会创建一个新的表记录
你可以通过 save 方法的参数调节它的行为
must_create:如果设为 True,则该方法会被强制处理为创建方法,当然如果数据中包含了已经被创建的主键,则会抛出错误must_update:如果设为 True,则该方法会被强制处理为更新方法,当无法完成更新(如缺少主键或者主键不存在时)会抛出错误transaction:设为 True 或者数据库连接的名称来开启对应数据库连接的 事务,默认不开启,设为 True 开启的是模型默认连接数据库的事务using:可以传入一个数据库连接名称字符串来指定保存到的数据库,默认将沿用对应模型的数据库配置(在 Django ORM 中默认为default数据库)
Tip
数据库连接的名字就是在 DatabaseConnections 中定义的数据库字典的键,如 'default'
下面以编写创建文章 API 为例展示了 save 方法在接口中的使用
from utilmeta.core import orm
from .models import Article
class ArticleCreation(orm.Schema[Article]):
content: str
author_id: int = orm.Field(no_input=True)
class ArticleAPI(API):
async def post(self, article: ArticleCreation = request.Body,
user: User = API.user_config):
article.author_id = user.pk
await article.asave()
return article.pk
from utilmeta.core import orm
from .models import Article
class ArticleCreation(orm.Schema[Article]):
content: str
author_id: int = orm.Field(no_input=True)
class ArticleAPI(API):
def post(self, article: ArticleCreation = request.Body,
user: User = API.user_config):
article.author_id = user.pk
article.save()
return article.pk
在这个例子中我们先定义了 ArticleCreation 类,其中包括了内容字段 content 和作者字段 author_id,其中作者字段配置了 no_input=True 不接受客户端的输入,这是因为通常对于这种内容创作接口,都会直接将【当前请求用户】作为新内容的【作者】字段,所以无需客户端提供
在 post 方法中,我们也通过属性赋值将当前用户的主键赋值给了请求数据的 author_id 字段,然后调用了 Schema 实例的保存方法,这样会将其中的数据保存到数据库中,并且将新记录的主键值赋值给 Schema 实例的 pk 属性
bulk_save - 批量保存数据¶
Schema.bulk_save(data) 会将一个列表数据批量保存,列表中每个元素都应该是一个 Schema 实例或者符合 Schema 声明的字典数据,这个方法会根据其中每个元素的数据分组执行批量创建或批量更新
下面是一个批量创建用户的接口示例
from utilmeta.core import api, orm, request
from .models import User
class UserSchema(orm.Schema[User]):
username: str
class UserAPI(api.API):
@api.post
async def bulk(self, data: List[UserSchema] = request.Body) -> List[UserSchema]:
return await UserSchema.abulk_save(data)
from utilmeta.core import api, orm, request
from .models import User
class UserSchema(orm.Schema[User]):
username: str
class UserAPI(api.API):
@api.post
def bulk(self, data: List[UserSchema] = request.Body) -> List[UserSchema]:
return UserSchema.bulk_save(data)
例子中的方法使用 List[UserSchema] 作为请求体的类型声明,表示接受一个列表 JSON 数据,接口将自动解析转化为 UserSchema 实例的列表,你只需要调用 UserSchema.bulk_save 方法即可将这个列表中的数据批量创建或更新
bulk_save 方法会返回保存好的 Schema 数据实例列表,为新创建的数据实例设置主键值,在上面的例子中把这个结果直接作为 API 函数的响应数据返回
除了第一个接受列表数据的参数外,bulk_save 方法还提供一些参数来调控其中的行为
must_create:如果设为 True,则列表中的元素会被强制创建,当然如果数据中包含了已经被创建的主键,则会抛出错误must_update:如果设为 True,则列表中的元素会被强制更新,当无法完成更新(如缺少主键或者主键不存在时)会抛出错误transaction:设为 True 或者数据库连接的名称来开启对应数据库连接的 事务,默认不开启,设为 True 开启的是模型默认连接数据库的事务using:可以传入一个数据库连接名称字符串来指定保存到的数据库,默认将沿用对应模型的数据库配置(在 Django ORM 中默认为default数据库)
commit - 更新查询集¶
由一个 orm.Schema 实例 调用,将其中的数据批量更新到查询集覆盖的所有记录
调用异步方法¶
当你调用 orm.Schema 的异步方法时,如 ainit,asave, aserialize 时,UtilMeta 底层将会实现异步的查询,一般来说,在异步 API 函数中,你应该使用 orm.Schema 的异步方法,比如
class ArticleAPI(api.API):
async def get(self, id: int) -> ArticleSchema:
return await ArticleSchema.ainit(id)
但即使你在异步函数中调用了 orm.Schema 的同步方法,比如
class ArticleAPI(api.API):
async def get(self, id: int) -> ArticleSchema:
return ArticleSchema.init(id)
例子中的接口仍然可以正常处理请求,但由于 Django 原生的查询引擎不支持直接在异步环境中执行,所以异步接口中的同步查询在 Django 实现上使用了线程池中的一个线程来处理
虽然 UtilMeta 的声明式 ORM 会根据运行的异步环境与 ORM 引擎自动调整执行策略,但是如果你在异步函数中直接使用 Django 的同步方法查询则会出现错误,比如
class ArticleAPI(api.API):
@api.get
async def exists(self, id: int) -> bool:
return Article.objects.filter(id=id).exists()
在调用时往往会得到错误
SynchronousOnlyOperation: You cannot call this from an async context
- use a thread or sync_to_async.
因为 Django 的同步查询方法使用的查询引擎是严格依赖当前线程的,你应该使用它们的异步变体(在方法名称前加上 a)
class ArticleAPI(api.API):
@api.get
async def exists(self, id: int) -> bool:
return await Article.objects.filter(id=id).aexists()
关系查询¶
在查询时返回关系对象的信息是非常常见的 Web 开发需求,如返回文章时需要对应的作者信息,返回订单时需要对应的商品信息等等,这些可以统称为关系查询,UtilMeta 的声明式 ORM 可以很简洁地处理这样的查询,下面详细介绍对应的用法
单个关系字段¶
你可以只查询关系对象的某个字段,声明的方式很简单,如下
class ArticleSchema(orm.Schema[Article]):
author_name: str = orm.Field('author.username')
例子中 author_name 字段通过声明 'author.username' 作为查询字段值来查询 author 外键对应的用户的 username 字段
除了外键外,你还可以查询多对关系中的单个字段,但是需要使用列表类型作为该字段的类型提示,如
class ArticleSchema(orm.Schema[Article]):
tag_list: List[str] = orm.Field('tags.name')
Article 模型有一个名为 'tags' 的多对多关系指向一个 Tag 模型,其中有着 name 字段,那么你就可以使用 'tags.name' 将文章关联的所有标签的 name 字段序列化成一个字符串列表
当然如果你使用 orm.Field('tags') 就会查询出关联的所有标签的主键值列表
查询关系对象¶
关系查询的常用方式是按照一定的结构将关联的对象整个序列化出来,比如上面例子中的文章-作者(author)字段,查询关系对象的方式很简单,就是把你期望的查询结构用 orm.Schema 声明出来后,作为关系字段的类型声明即可
对于 外键 字段,只会对应一个关系对象,所以你直接指定 Schema 类即可,比如
from utilmeta.core import orm
from .models import User, Article
from django.db import models
class UserSchema(orm.Schema[User]):
username: str
articles_num: int = models.Count('articles')
class ArticleSchema(orm.Schema[Article]):
id: int
author: UserSchema
content: str
author 字段就直接指定了 UserSchema 作为类型声明,在序列化时 author 字段会得到对应的 UserSchema 实例
使用 Optional
当你要查询的外键关系对象可能为 None 时 (模型字段声明了 null=True),你应该使用 Optional[Schema] 来作为对应的类型声明
对于 多对多 / 多对一 等可能包含多个关系对象的字段,你应该使用 List[Schema] 作为类型声明,比如
from utilmeta.core import api, orm
from .models import User, Article
from django.db import models
class ArticleSchema(orm.Schema[Article]):
id: int
author_name: str = orm.Field('author.username')
content: str
class UserSchema(orm.Schema[User]):
username: str
articles: List[ArticleSchema]
UserSchema 中的 articles 字段指定了 List[ArticleSchema] 作为类型声明,在序列化时 articles 字段会得到用户所创作的所有文章的列表(如果没有,则会是一个空列表)
自动优化执行避免 N + 1 问题
N + 1 问题是当你使用循环进行多对关系的查询时,如果没有特别优化,可能会对数据库做出相当于循环次数(查询集的长度) + 1 次查询,性能会受到很大影响,比如类似于下面的代码
for user in user_queryset:
articles = Article.objects.filter(author=user).values()
定制查询集¶
对于 多对 关系对象的查询,我们有时需要对关系对象列表进行定制化的过滤或排序,此时你可以使用 orm.Field 的 queryset 参数直接指定一个查询集,比如下面的例子会为每个用户查询点赞数最多的文章列表
from utilmeta.core import api, orm
from .models import User, Article
from django.db import models
class ArticleSchema(orm.Schema[Article]):
id: int
author_name: str = orm.Field('author.username')
content: str
class UserSchema(orm.Schema[User]):
username: str
most_liked_articles: List[ArticleSchema] = orm.Field(
'articles',
queryset=Article.objects.annotate(
likes_num=models.Count('liked_bys')
).filter(
likes_num__gt=0
).order_by('-likes_num')
)
在这个例子中,我们使用 queryset 参数为 most_liked_articles 字段指定了一个定制的查询集,过滤掉没有被赞的文章,并按照文章的赞数进行排序
指定 queryset 的前提是字段需要指定一个明确的 多对关系名称,可以用 orm.Field 的第一个参数(如上面例子中的 'articles')或者字段的属性名进行指定
不要切片
请 不要 对指定的 queryset 查询集进行切片处理(比如限制返回结果数量),因为为了优化 N + 1 查询问题, queryset 查询集的查询实现是一次性查询全部的关系对象并按照对应关系进行分发,如果你将查询集进行切片,查询出的实例所分配到的关系对象列表可能是不完整的,如果你需要实现类似 “为每个实例查询最多 N 条关系对象” 的需求,请参考下方的 关系查询函数 进行实现
单条关系对象查询¶
当你只需要查询 1 个 目标关系对象时,这时你可以直接把查询集声明出来,UtilMeta 会将其处理成一条 subquery 子查询 从而压缩到单条查询,比如
class ArticleSchema(orm.Schema[Article]):
id: int
content: str
class UserSchema(orm.Schema[User]):
username: str
top_article: Optional[ArticleSchema] = orm.Field(
Article.objects.annotate(
favorites_num=models.Count('favorited_bys')
).filter(
author_id=models.OuterRef('pk')
).order_by('-favorites_num')[:1]
)
OuterRef
OuterRef 是 Django 中用于引用外部查询的字段的用法,在例子中实际上引用的目标 User 模型查询集的主键值
关系查询函数¶
关系查询函数提供了一个可以自定义的函数钩子,你可以为关系查询编写任意的条件,比如添加过滤和排序条件,控制数量等
我们以一个需求作为例子,假设我们需要查询一个用户列表,其中每个用户都需要附带 “当前请求用户的关注者中有哪些关注了目标用户”,这在微博,Twitter(X) 等社交媒体中是常见的需求,在前端大概会展示为 “你关注的 A, B 也关注了他” 或 “Followers you known”,这样的需求就可以使用关系查询函数简单高效地实现
from utilmeta.core import orm, request
class UserSchema(orm.Schema[User]):
username: str
@classmethod
def get_followers_you_known(cls, *pks, user_id: int = request.var.user_id):
mp = {}
for val in User.objects.filter(
followings__in=pks,
followers=user_id
).values('followings', 'pk').using(db_using):
mp.setdefault(val['followings'], []).append(val['pk'])
return mp
followers_you_known: List[UserBase] = orm.Field(
get_followers_you_known,
default_factory=list
)
例子中 UserSchema 定义了一个类函数,从而可以为不同的请求用户生成不同的查询,在其中我们定义了一个 get_followers_you_known 查询函数,使用 *pks 接受 当前查询到的 Schema 实例的主键列表 并构造出了一个字典,为每个主键映射到一个 目标关系的主键列表(即 Followers you known 的用户主键列表),之后返回这个字典,UtilMeta 会完成后续的聚合查询以及结果分发,最后每个用户 Schema 实例的 followers_you_known 字段都会包含满足条件要求的查询结果
Tip
在查询函数中可以使用 request.var 中的属性作为参数默认值声明请求的上下文参数,常用的包括:
request.var.user_id:当前请求用户 ID,
request.var.user: 当前请求用户实例,
request.var.ip: 当前请求 IP 地址
在调用时,将 init / serialize 方法的 context 参数传入当前请求对象(self.request) ,例如 UserSchema.init(1, context=self.request) 即可完成请求上下文字段的查询
关系值查询函数¶
关系查询函数除了可以使用其定义的关系 Schema 对象查询关系对象外,还可以直接查询关系表中的字段值,即不需要进行进一步的序列化,而是直接将查询函数中的结果输出,那么只需要完成主键与字段值的对应即可定义值查询函数,比如下面的例子
from .models import User, Article
class UserQuerySchema(orm.Schema[User]):
id: int
username: str
@classmethod
def get_article_tags(cls, *pks):
mp = {}
for tags, author_id in Article.objects.filter(
author__in=pks,
).values_list('tags', 'author_id'):
mp.setdefault(author_id, set()).update(tags or [])
return mp
article_tags: Set[str] = orm.Field(get_article_tags)
这个例子中我们定义的 article_tags 并不直接对应模型字段,而是使用 get_article_tags 函数把文章作者与作者所有文章的标签进行对应,就可以得到每个作者的全部文章标签集合
get_article_tags 就是关系值查询函数,这是一种方便且高效地组织查询代码的方式,比如上面的例子就使用一条查询完成了任意数量用户的文章标签查询
表达式查询¶
对于某个关系字段的聚合或计算也是常见的开发需求,比如
- 查询用户有多少关注者或关注的人
- 查询文章有多少人喜欢,浏览以及评论
- 查询商品有多少订单
几乎含有关系字段的模型都需要对应关系的数量查询,对于 Django ORM,你可以使用 models.Count('<relation_name>') 来查询对应关系的数量,比如上面例子中的
from utilmeta.core import orm
from .models import User
from django.db import models
class UserSchema(orm.Schema[User]):
username: str
articles_num: int = models.Count('articles')
UserSchema 的 articles_num 字段使用 models.Count('articles') 表示查询 'articles' 关系的数量,也就是查询一个用户创作了多少文章
除了数量外,表达式查询还可以用于一些常用的数据计算,比如
models.Avg:平均值计算,比如计算一个店铺或商品的平均评分models.Sum:求和计算,比如计算一个商品的总销售额models.Max:最大值计算models.Min:最小值计算
表达式可以直接作为字段的属性值,也可以作为第一个参数传入 orm.Field 中,这样你可以指定更多的字段配置,比如
from utilmeta.core import orm
from .models import User
from django.db import models
class UserSchema(orm.Schema[User]):
username: str
articles_num: int = orm.Field(
models.Count('articles'),
title='文章数量',
default=0
)
Tip
关于 Django 的聚合表达式的更多用法可以参考 Django 聚合表达式文档
以下是一些实际开发时常用到的表达式类型
Exists¶
有时你需要返回一个条件查询集是否存在的字段,比如查询一个用户时返回【当前请求的用户是否已经关注了该用户】,你就可以使用 Exists 表达式
from utilmeta.core import orm, request
from django.db import models
class UserSchema(orm.Schema[User]):
username: str
@classmethod
def get_followed(cls, user_id: int = request.var.user_id):
return models.Exists(
User.objects.filter(
pk=user_id,
followers=exp.OuterRef('pk')
)
)
followed: bool = orm.Field(get_followed, default=False)
我们使用请求上下文参数的声明方式,使用 followed 字段查询当前的请求用户(request.var.user_id)是否关注了此用户
SubqueryCount¶
对于一些关系计数你可能需要增加一些条件,比如查询一篇文章时需要返回【当前用户的关注用户中有多少人喜欢该文章】,这时你可以使用 SubqueryCount 表达式
from utilmeta.core import orm, request
from utilmeta.core.orm.backends.django import expressions as exp
class ArticleSchema(orm.Schema[Article]):
id: int
content: str
@classmethod
def get_following_likes(cls, user_id: int = request.var.user_id):
return exp.SubqueryCount(
User.objects.filter(
followers=user_id,
likes=exp.OuterRef('pk')
)
)
following_likes: int = orm.Field(get_following_likes, default_factory=list)
我们使用请求上下文参数的声明方式,使用 following_likes 字段查询当前的请求用户(request.var.user_id)的关注用户中有多少人喜欢该文章
orm.Schema 的使用¶
这一节将介绍 orm.Schema 常用的使用方式和应用技巧
orm.Field 字段参数¶
在 orm.Schema 中声明的每个字段都可以指定一个 orm.Field(...) 作为属性值,从而配置这个字段的行为,下面是常用的字段配置参数
首先是第一个参数 field,当你需要查询的字段不在当前模型上(无法直接表示为 Schema 类的属性名称)时,你就可以使用这个参数指定你要查询的字段值,上文的例子已经示例了相关的用法,比如
- 传入一个关系查询字段,比如
orm.Field('author.username') - 传入一个关系查询函数,比如
orm.Field(get_top_comments) - 传入一个查询集
- 传入一个查询表达式,比如
orm.Field(models.Count('articles'))
除了首个参数,你还可以使用以下参数实现更多的字段行为
no_input:设为 True 可以忽略字段输入,例如在创建文章时author_id字段不应该由请求数据提供,而是应该在 API 函数中赋值为当前请求的用户 ID,所以需要声明no_input=Trueno_output:设为 True 可以忽略字段输出,例如在创建文章时可以要求请求数据包含一个标签列表,但并不需要保存在文章模型实例中,而是在 API 函数里自行处理标签的创建与赋值,此时就可以声明no_output=Truemode:你可以为字段指定一个模式,让字段只在对应的模式中起作用,这样你可以使用一个 Schema 类处理查询,创建,更新等多种场景,在 Realworld 博客项目 中有对字段模式使用的详细示例
字段参数配置
orm.Field 继承自 utype.Field,所以其中详细的字段参数用法可以参考 utype - 字段配置文档
@property 属性字段¶
你可以巧妙利用 Schema 类的 @property 属性字段快速开发基于查询结果数据计算的字段,比如
from datetime import datetime
class UserSchema(orm.Schema[User]):
username: str
signup_time: datetime
@property
def joined_days(self) -> int:
return int((datetime.now() - self.signup_time).total_seconds() / (3600 * 24))
例子中 joined_days 属性通过用户的注册时间计算出用户已注册的天数作为字段的值输出
继承与组合¶
orm.Schema 类同样可以使用类的继承,组合等方式复用声明的字段,例如
from utilmeta.core import orm
from .models import User
class UsernameMixin(orm.Schema[User]):
username: str = orm.Field(regex='[A-Za-z0-9_]{1,20}')
class UserBase(UsernameMixin):
bio: str
image: str
class UserLogin(orm.Schema[User]):
email: str
password: str
class UserRegister(UserLogin, UsernameMixin): pass
在例子中我们定义了
UsernameMixin:只包含username一个字段,可以被其他 Schema 类复用UserBase:继承 UsernameMixin,定义用户的基本信息UserLogin:用户登录所需的参数UserRegister:用户注册所需的参数,就是把登录参数 UserLogin 与包含用户名参数的 UsernameMixin 进行组合
以上所有的 Schema 类都可以独立使用和查询
模型继承¶
Django 模型可以使用类继承的方式复用模型字段,比如
from django.db import models
class BaseContent(models.Model):
body = models.TextField()
created_at = models.DateTimeField(auto_now_add=True)
updated_at = models.DateTimeField(auto_now=True)
class Meta:
abstract = True
class Article(BaseContent):
slug = models.SlugField(db_index=True, max_length=255, unique=True)
title = models.CharField(db_index=True, max_length=255)
description = models.TextField()
author = models.ForeignKey('user.User', on_delete=models.CASCADE, related_name='articles')
tags = models.ManyToManyField(Tag, related_name='articles')
class Comment(BaseContent):
article = models.ForeignKey(Article, related_name='comments', on_delete=models.CASCADE)
author = models.ForeignKey('user.User', on_delete=models.CASCADE, related_name='comments')
上面例子中就把 Article 文章模型和 Comment 评论模型中重复的字段整合到 BaseContent 抽象模型中,在 ORM Schema 类中也可以使用类似的技巧复用字段,对于 Schema 基类,你可以不指定模型,在继承时再注入,比如
from utype.types import *
from utilmeta.core import orm
from domain.user.schema import UserSchema
from .models import Comment, Article
class ContentSchema(orm.Schema):
body: str
created_at: datetime
updated_at: datetime
author: UserSchema
author_id: int = orm.Field(mode='a', no_input=True)
class CommentSchema(ContentSchema[Comment]):
id: int = orm.Field(mode='r')
article_id: int = orm.Field(mode='a', no_input=True)
class ArticleSchema(ContentSchema[Article]):
id: int = orm.Field(no_input=True)
slug: str = orm.Field(no_input='aw', default=None, defer_default=True)
title: str = orm.Field(default='', defer_default=True)
description: str = orm.Field(default='', defer_default=True)
在例子中我们定义了 ContentSchema 基类,承载文章和评论中通用的数据结构,但没有注入模型,之后声明的 CommentSchema 与 ArticleSchema 都继承自它并注入了对应的模型
Warning
没有注入模型的 orm.Schema 无法用于查询,比如例子中的 ContentSchema
orm.Query 查询参数¶
UtilMeta 的声明式 ORM 还支持声明模型的查询参数,如过滤条件,排序,数量控制等,下面就是一个简单的例子,你可以直接为文章的查询接口添加 ID 与作者的过滤参数
from utilmeta.core import orm
class ArticleQuery(orm.Query[Article]):
id: int
author_id: int
class ArticleAPI(api.API):
async def get(self, query: ArticleQuery) -> List[ArticleSchema]:
return await ArticleSchema.aserialize(query)
from utilmeta.core import orm
class ArticleQuery(orm.Query[Article]):
id: int
author_id: int
class ArticleAPI(api.API):
def get(self, query: ArticleQuery) -> List[ArticleSchema]:
return ArticleSchema.serialize(query)
我们使用类似 orm.Schema 的语法,用 orm.Query[<model>] 来声明一个模型的查询参数,声明的 Query 类用于API 函数参数的类型声明时会被自动处理为请求的查询参数(request.Query),你可以在函数中直接把它的实例传递给 orm.Schema 的 serialize 方法,序列化出对应的查询结果
过滤参数¶
在 orm.Query 类中声明的字段,如果在模型中有着同名字段的话,都会被自动处理为一个 过滤参数,当请求提供了这个过滤参数时,就会为目标查询增加对应的条件:比如当请求 GET /article?author_id=1 时,就会得到 author_id=1 的文章查询集
当你需要定义更复杂的查询参数时,就需要使用到 orm.Filter 组件了,下面示例一下过滤参数的常见用法
from utilmeta.core import orm
from datetime import datetime
from django.db import models
class ArticleQuery(orm.Query[Article]):
author: str = orm.Filter('author.username')
keyword: str = orm.Filter('content__icontains')
favorites_num: int = orm.Filter(models.Count('favorited_bys'))
within_days: int = orm.Filter(query=lambda v: models.Q(
created_at__gte=datetime.now() - timedelta(days=v)
))
class ArticleAPI(api.API):
def get(self, query: ArticleQuery) -> List[ArticleSchema]:
return ArticleSchema.serialize(query)
orm.Filter 的第一个参数可以指定查询字段的名称,几种类型都在例子中有体现
author:查询关系字段'author.username',即作者用户的用户名keyword:查询字段content大小写不敏感地包含(icontains)目标参数,即简单的搜索favorites_num:查询字段是一个关系计数表达式models.Count('favorited_bys'),即喜欢人数
另外,orm.Filter 还可以使用 query 参数指定一个查询表达式,接收一个参数(就是请求中对应的查询参数值),返回一个查询表达式,在 Django 中应该是一个 models.Q 表达式,其中可以包含自定义的查询条件,比如例子中的 within_days 查询的是在创建的几天内的文章
Tip
对于 Django 中更多的查找方法(指定 WHERE 子句的方法,比如例子中的 icontains),可以参考 Django 字段查找文档
orm.Filter 与 orm.Field 一样都继承自 utype.Field,所以其他的字段配置也依然有效,比如
required:是否必须,默认orm.Filter是required=False的,也就是非必须参数,只有当请求提供时才会应用相应的查询条件default:指定查询参数的默认值alias:指定查询参数的别名
搜索参数¶
一类常用的查询参数的作用是模糊匹配目标的一个或多个字段进行搜索,这样的搜索参数在 UtilMeta 中可以使用 orm.Search 参数定义,如
from utilmeta.core import orm
from datetime import datetime
from django.db import models
class ArticleQuery(orm.Query[Article]):
search: str = orm.Search(
Article.title,
Article.content,
Article.slug,
Article.tags
)
class ArticleAPI(api.API):
def get(self, query: ArticleQuery) -> List[ArticleSchema]:
return ArticleSchema.serialize(query)
orm.Search 可以接收一系列模型中可用于搜索的字段的字符串或引用(一般包含模型主要信息的文本字符串,如标题,概要,描述说明等),此外还有一些参数可供选择:
case_sensitive: 大小写敏感,默认为 Falsekeyword_delimiters: 指定关键词的分隔符,搜索时会先将搜索文本分割成关键词,再对字段进行查询匹配,默认为(' ', ',', ';', '|')match_mode: 字段与关键词的匹配模式,目前支持的包括:orm.Search.ANY_ANY: 任意字段匹配任意关键词即可,最为宽松的搜索orm.Search.UNION_ALL: 实例的可搜索字段匹配所有的关键词(可以分步在任意一个或多个字段)即可orm.Search.ANY_ALL: 任意单个可搜索字段需要匹配所有的关键词,默认方式orm.Search.ALL_ALL: 所有的字段都需要匹配所有的关键词,最严格的搜索
Note
UtilMeta >= 2.8.0 支持 orm.Search 搜索参数
排序参数¶
orm.Query 类中还可以声明用于控制查询结果排序的字段,你可以把支持的排序字段和对应的配置声明出来,示例如下
from utilmeta.core import orm
from django.db import models
from .models import Article
class ArticleQuery(orm.Query[Article]):
order: List[str] = orm.OrderBy({
"comments_num": orm.Order(field=models.Count("comments")),
"favorited_num": orm.Order(field=models.Count("favorited_bys")),
Article.created_at: orm.Order(),
})
class ArticleAPI(api.API):
def get(self, query: ArticleQuery) -> List[ArticleSchema]:
return ArticleSchema.serialize(query)
首先排序参数需要使用 orm.OrderBy 字段声明,其中定义一个字典来声明排序选项,字典的键是排序选项的名称,值是排序的配置
声明了排序参数后,客户端可以传入一个排序选项的列表,排序选项从排序参数的声明中选择,可以在选项前添加 - (负号)表示按照这个选项的 倒序 排列,比如对于上文的例子,当客户端请求 GET /article?order=-favorited_num,created_at 时,检测到的排序选项为
-favorited_num:按照喜欢人数的倒序排序,人数越多越靠前created_at:按照创建时间正序排序,越早越靠前
排序参数支持的每一个排序选项都可以由 orm.Order 来配置,其中支持的参数有
field:可以指定排序的目标字段或者表达式,如果对应的排序选项的名称就是模型字段的名称,则可以不指定(比如例子中的created_at)asc:是否支持正序排列,默认为 True,如果设为 False 则表示不提供正序排列desc:是否支持倒序排列,默认为 True,如果设为 False 则表示不提供倒序排列document:为排序字段指定一个文档字符串,会被整合到 API 文档中
在排序中,有一类值是比较难处理,就是 null 值,在查询时,字段值为 null 的结果应该排列在最前,最后,还是将其过滤掉,由下面几个参数确定
notnull:是否需要将该字段为 null 值的实例过滤掉,默认为 Falsenulls_first:将该排序字段为 null 值的实例排列在最前(正序为最前,倒序为最后)nulls_last:将该排序字段为 null 值的实例排列在最后(正序为最后,倒序为最前)
如果这些参数都不指定的话,排序字段为 null 值的实例的排序将会由数据库决定
数量控制参数(分页参数)¶
在实际开发中,我们不太可能会把查询命中的成百上千条记录一次性返回,而是会需要提供 分页控制 的机制,orm.Query 类中也支持定义几种被预设好的分页参数让你快速实现分页查询接口,下面是一个例子
from utilmeta.core import orm
from django.db import models
from .models import Article
class ArticleQuery(orm.Query[Article]):
offset: int = orm.Offset(default=0)
limit: int = orm.Limit(default=20, le=100)
class ArticleAPI(api.API):
def get(self, query: ArticleQuery) -> List[ArticleSchema]:
return ArticleSchema.serialize(query)
例子中定义的两个分页控制参数如下
offset:指定一个orm.Offset字段,控制查询的起始偏移量,比如客户端已经查询了 30 条结果,下一个请求将会发送?offset=30来查询 30 条后的结果limit:指定一个orm.Limit字段,用于控制查询的返回结果数量限制,其中指定了默认值为 20,也就是当这个参数没有提供时最多返回 20 条结果,并指定了最大值为 100,请求的参数不能大于这个值
比如当客户端请求 GET /article?offset=10&limit=30 就会返回查询结果中的 10~40 条
除了 offset / limit 模式,还有一种方式是客户端直接传递分页的 ”页数“,比如
from utilmeta.core import orm
from django.db import models
from .models import Article
class ArticleQuery(orm.Query[Article]):
page: int = orm.Page()
rows: int = orm.Limit(default=20, le=100)
class ArticleAPI(api.API):
def get(self, query: ArticleQuery) -> List[ArticleSchema]:
return ArticleSchema.serialize(query)
例子中的 page 参数指定一个 orm.Page 字段,完全对应前端的页数概念,从 1 开始计数,比如当客户端请求 GET /article?page=2&rows=10 时会返回查询结果中的 10~20 条,即客户端数据中的 ”第 2 页“
count() 获取结果总数¶
为了能够让客户端显示查询的总页数,我们往往页需要返回查询的结果总数(忽略分页参数),为了应对这一需求,orm.Query 实例提供了一个 count() 方法(异步变体为 acount())
下面演示了一个博客项目的文章分页接口是如何处理的
from utilmeta.core import orm, api, response
class ArticlesResponse(response.Response):
result_key = 'result'
count_key = 'count'
result: List[ArticleSchema]
class ArticleAPI(api.API):
class ListArticleQuery(orm.Query[Article]):
author: str = orm.Filter('author.username')
offset: int = orm.Offset(default=0)
limit: int = orm.Limit(default=20, le=100)
async def get(self, query: ListArticleQuery) -> ArticlesResponse:
return ArticlesResponse(
result=await ArticleSchema.aserialize(query),
count=await query.acount()
)
from utilmeta.core import orm, api, response
class ArticlesResponse(response.Response):
result_key = 'result'
count_key = 'count'
result: List[ArticleSchema]
class ArticleAPI(api.API):
class ListArticleQuery(orm.Query[Article]):
author: str = orm.Filter('author.username')
offset: int = orm.Offset(default=0)
limit: int = orm.Limit(default=20, le=100)
def get(self, query: ListArticleQuery) -> ArticlesResponse:
return ArticlesResponse(
result=ArticleSchema.serialize(query),
count=query.count()
)
在例子中我们使用响应模板定义了一个嵌套的响应结构,同时包括查询结果(result)与查询的总数(count),在函数中也对应传入了使用 ArticleSchema 序列化的列表数据,与调用 query.count() 得到的结果总数
这样当客户端收到了 count 数据后,就可以计算出显示的总页数
let pages = Math.ceil(count / rows_per_page)
字段控制参数¶
UtilMeta 还提供了一种类似 GraphQL 的结果字段控制机制,能够让客户端选择返回哪些字段或者排除哪些字段,进一步优化接口的查询效率,示例如下
from utilmeta.core import orm
from .models import User, Article
from django.db import models
from datetime import datetime
class UserSchema(orm.Schema[User]):
username: str
articles_num: int = models.Count('articles')
class ArticleSchema(orm.Schema[Article]):
id: int
author: UserSchema
content: str
created_at: datetime
favorites_count: int = models.Count('favorited_bys')
class ArticleQuery(orm.Query[Article]):
scope: List[str] = orm.Scope()
exclude: List[str] = orm.Scope(excluded=True)
class ArticleAPI(api.API):
def get(self, query: ArticleQuery) -> List[ArticleSchema]:
return ArticleSchema.serialize(query)
在 ArticleQuery 中我们定义了一个名为 scope 的 orm.Scope 参数,客户端可以使用这个参数指定一个字段列表,使得结果只返回这个列表中的字段,比如请求 GET /article?scope=id,content,created_at 就只会返回 id, content 以及 created_at 字段
另外一个 exclude 参数也使用了 orm.Scope,但在其中指定了 excluded=True,也就是说会排除参数中给出的字段,当请求 GET /article?exclude=author 就会返回不包含 author 字段的结果数据
Note
客户端合理使用字段控制参数不仅可以降低带宽资源消耗,也能降低对应的查询压力,因为 UtilMeta 框架会根据 scope 参数中指定的字段对生成的查询语句进行剪裁,只会查询需要包含在结果中的字段,这样如果某些字段的查询消耗较大(如复杂的嵌套多对关系对象或表达式查询),当这些字段不包含在期望结果字段中时便不会进行查询处理
get_queryset 获取查询集¶
对于 orm.Query 实例,除了作为 serialize 等方法的参数直接进行序列化外,你还可以调用它的 get_queryset 方法获取生成的查询集,比如对于 Django 模型,就会生成一个 Django QuerySet
get_queryset 方法还可以接受一个 base_queryset 参数,可以在这个查询集的基础上增加查询参数中包含的过滤,排序,分页效果`
class ArticleAPI(API):
class ListArticleQuery(orm.Query[Article]):
author: str = orm.Filter('author.username', required=True)
offset: int = orm.Offset(default=0)
limit: int = orm.Limit(default=20, le=100)
scope: dict = orm.Scope()
@api.get
async def list(self, query: ListArticleQuery):
return await ArticleSchema.aserialize(
queryset=query.get_queryset(
Article.objects.exclude(comments=None)
),
context=query.get_context()
)
例子中我们使用了 query.get_queryset 方法获取查询参数生成的查询集,并传入了一个自定义的基础 QuerySet,将生成查询集结果传递给序列化方法的 queryset 参数
Tip
字段控制参数是比较特殊的查询参数,它虽然并不会对查询集造成任何影响,但是会影响序列化的字段,需要通过 query.get_context() 传递
DISTINCT 去重¶
默认情况下,为了提高查询性能,orm.Query 生成的查询将不会进行 DISTINCT 去重,对于一般的字段查询,基本不会产生重复的 ID,但是如果你的查询中包含了复杂的关系查询,或者在 get_queryset() 时传入了未去重的含有重复行的查询集,那么就会导致重复的行
为了解决这个问题,orm.Query 提供了一个可覆盖的 __distinct__ 属性,可以用于指定是否强制去重,如果设为 True,那么它生成的查询集都是强制去重后的
class ListArticleQuery(orm.Query[Article]):
__distinct__ = True
数据库与 ORM 配置¶
我们介绍了 UtilMeta 声明式 ORM 的用法,但如果需要接入数据库使用,还需要完成数据库与 ORM 的配置
作为元框架,UtilMeta 的声明式 ORM 能够支持一系列的 ORM 引擎作为模型层实现,目前的支持状态是
- Django ORM:已完全支持
- tortoise-orm:即将支持
- peewee:即将支持
- sqlachemy:即将支持
所以我们以 Django ORM 为例,示例如何配置数据库连接与模型
首先假设你的项目使用如下命令创建
meta setup blog --temp=full
文件夹结构类似
/blog
/config
conf.py
service.py
/domain
/article
models.py
/user
models.py
/service
api.py
main.py
meta.ini
你可以在 config/conf.py 中配置如下代码
from utilmeta import UtilMeta
from config.env import env
def configure(service: UtilMeta):
from utilmeta.core.server.backends.django import DjangoSettings
from utilmeta.core.orm import DatabaseConnections, Database
service.use(DjangoSettings(
apps_package='domain',
secret_key=env.DJANGO_SECRET_KEY
))
service.use(DatabaseConnections({
'default': Database(
name='db',
engine='sqlite3',
)
}))
service.setup()
from utilmeta import UtilMeta
from config.conf import configure
from config.env import env
import starlette
service = UtilMeta(
__name__,
name='blog',
backend=starlette,
production=env.PRODUCTION,
)
configure(service)
我们在 config/conf.py 中定义了 configure 函数进行服务配置,接收 UtilMeta 类型的服务实例,使用 use() 方法进行配置
使用 Django ORM 需要完成 Django 的配置,UtilMeta 提供了 DjangoSettings 来简便地配置 Django,其中重要的参数有
apps_package:指定一个目录,其中的每个文件夹都会被当作一个 Django App,Django 会扫描其中的models.py文件检测所有的模型,比如例子中的'domain'apps:你也可以指定一个 Django App 的引用列表,来单独列出所有的模型目录,比如['domain.article', 'domain.user']secret_key:指定一个密钥,你可以使用环境变量来管理
数据库连接¶
在 UtilMeta 中,你可以使用 DatabaseConnections 进行数据库连接配置,其中可以传入一个字典,字典的键是数据库连接的名称,我们沿用 Django 定义数据库连接的语法,使用 'default' 表示默认的连接,对应的值是一个 Database 实例,用于配置具体的数据库连接,其中的参数包括
name:数据库的名称(在 SQLite3 中是数据库文件的名称)engine:数据库引擎,Django ORM 支持的引擎有sqlite3,mysql,postgresql,oracleuser:数据库的用户名password:数据库的用户密码host:数据库的主机,默认为本地(127.0.0.1)port:数据库的端口号,默认根据数据库的类型决定,如mysql为 3306,postgresql为 5432
SQLite3
例子中使用的数据库是 SQLite3,它无需你提供用户名,密码和主机等信息,而是会直接在你的项目根目录中创建一个以 name 参数为名称的文件来存储数据,适合本地快速搭建与调试
PostgreSQL / MySQL
当你需要使用 PostgreSQL 或 MySQL 这种需要提供数据库密码的连接时,我们建议你使用环境变量来管理这些敏感信息,示例如下
from utilmeta import UtilMeta
from config.env import env
def configure(service: UtilMeta):
from utilmeta.core.server.backends.django import DjangoSettings
from utilmeta.core.orm import DatabaseConnections, Database
service.use(DjangoSettings(
apps_package='domain',
secret_key=env.DJANGO_SECRET_KEY
))
service.use(DatabaseConnections({
'default': Database(
name='blog',
engine='postgresql',
host=env.DB_HOST,
user=env.DB_USER,
password=env.DB_PASSWORD,
port=env.DB_PORT,
)
}))
service.setup()
from utilmeta.conf import Env
class ServiceEnvironment(Env):
PRODUCTION: bool = False
DJANGO_SECRET_KEY: str = ''
DB_HOST: str = '127.0.0.1'
DB_PORT: int = None
DB_USER: str
DB_PASSWORD: str
env = ServiceEnvironment(sys_env='BLOG_')
在 config/env.py 中,我们将配置需要的密钥信息声明了出来,在初始化参数中传入了 sys_env='BLOG_',表示会拾取前缀为 BLOG_ 的环境变量,所以你可以指定类似如下的环境变量
BLOG_PRODUCTION=true
BLOG_DJANGO_SECRET_KEY=your_key
BLOG_DB_USER=your_user
BLOG_DB_PASSOWRD=your_password
接着初始化后的 env 就会将环境变量解析为对应的属性并完成类型转化,你就可以直接在配置文件中使用它们了
Django 数据迁移¶
当我们编写好数据模型后即可使用 Django 提供的迁移命令方便地创建对应的数据表了,如果你使用的是 SQLite,则无需提前安装数据库软件,否则需要先安装 PostgreSQL 或 MySQL 数据库到你的电脑或者线上环境,然后创建一个与你的连接配置的 name 一样的数据库,数据库准备完毕后就可以使用如下命令完成数据迁移了
meta makemigrations
meta migrate
当看到以下输出时即表示迁移成功
Operations to perform:
Apply all migrations: article, contenttypes, user
Running migrations:
Applying article.0001_initial... OK
Applying user.0001_initial... OK
Applying article.0002_initial... OK
Applying contenttypes.0001_initial... OK
Applying contenttypes.0002_remove_content_type_name... OK
对于 SQLite 数据库会直接创建出对应的数据库文件和数据表,其他的数据库则会按照你的模型定义创建出对应的数据表
数据库迁移命令
以上的命令是 Django 的数据库迁移命令,makemigrations 会把数据模型的变更保存为迁移文件,而 migrate 命令则会把迁移文件转化为创建或调整数据表的 SQL 语句执行
异步查询¶
异步查询并不需要额外的配置,而是取决于你的调用方式,如果你使用了 orm.Schema 的异步方法,如 ainit, aserialize, asave 等,那么在内部就会调用异步查询的实现方式
Django ORM 中的每个方法也有相应的异步实现,但实际上它只是使用 sync_to_async 方法将同步的函数整体转变为一个异步函数,其内部查询逻辑和驱动的实现依然全部是同步与阻塞的
AwaitableModel
UtilMeta ORM 完成了 Django ORM 中所有方法的纯异步实现,使用 encode/databases 库作为各个数据库引擎的异步驱动,最大程度发挥了异步查询的性能,承载这一实现的模型基类位于
from utilmeta.core.orm.backends.django.models import AwaitableModel
如果你的 Django 模型继承自 AwaitableModel,那么它的所有 ORM 方法都会是完全异步实现的
ACASCADE
需要注意的是,当你使用 AwaitableModel 对于外键的 on_delete 选项,如果需要选择 级联删除 时,应该使用 utilmeta.core.orm.backends.django.models.ACASCADE,这个函数是 django.db.models.CASCADE 的异步实现
而 encode/databases 其实也是分别集成了如下的异步查询驱动
所以如果你在选择数据库时还需要指定它的异步查询引擎,你可以在 engine 参数中以 sqlite3+aiosqlite,postgresql+asyncpg 的方式传递
事务插件¶
事务也是数据查询和操作时非常重要的机制,保障了某一系列操作的原子性(要么整体成功,要么整体失败不产生影响)
UtilMeta 中可以使用 orm.Atomic 接口装饰器为接口启用数据库事务,我们已文章的创建接口为例展示相应的用法
from utilmeta.core import orm
class ArticleAPI(API):
@orm.Atomic('default')
async def post(self, article: ArticleSchema[orm.A] = request.Body,
user: User = API.user_config):
tags = []
for name in article.tag_list:
tag, created = await Tag.objects.aget_or_create(name=name)
tags.append(tag)
article.author_id = user.pk
await article.asave()
if self.tags:
# create or set tags relation in creation / update
await self.article.tags.aset(self.tags)
这个例子中的 post 接口在创建文章时,还需要完成标签的创建和设置,我们直接在接口函数上使用 @orm.Atomic('default') 装饰器,表示对于 'default' (对应在 DatabaseConnections 定义的数据库连接)数据库开启事务,这个函数如果成功完成执行,那么事务将得到提交,如果中间出现了任何错误(Exception)那么事务将会回滚
所以在例子中,文章和标签要么同时创建和设置成功,要么整体失败对数据库中的数据不产生任何影响